
Veri yükleme motoru
Gato GraphQL, veri modelini temsil etmek için sunucu taraflı bileşenler kullanır (grafikler veya ağaçlar yerine). GraphQL sorgusunu çözümlemek üzere veri yükleme sürecini nasıl yürüttüğüne bakalım.
Verileri işleyebilmek için bileşenleri türlere düzleştirmemiz (<FeaturedDirector> => Director, <Film> => Film, <Actor> => Actor), bunları bileşen hiyerarşisinde göründükleri sıraya göre düzenlememiz (Director, ardından Film, ardından Actor) ve her tür için nesne verilerini kendi "yinelemesinde" alarak bunları "yinelemeler" halinde ele almamız gerekir:

Sunucunun veri yükleme motoru, verileri yüklemek için aşağıdaki (sözde) algoritmayı uygulamalıdır:
Hazırlık:
- Veritabanından alınması gereken nesnelerin ID listesini türe göre düzenlenmiş şekilde saklamak için boş bir kuyruk hazırla (her giriş şu biçimde olacak:
[tür => ID listesi]) - Öne çıkan yönetmen nesnesinin ID'sini al ve
Directortürü altında kuyruğa ekle
Kuyrukta başka giriş kalmayana kadar döngü:
- Kuyruktan ilk girişi al: tür ve ID listesi (örn.:
Directorve[2]), ardından bu girişi kuyruktan kaldır - Türün
TypeDataLoadernesnesini kullanarak, söz konusu ID'lere sahip tüm nesneleri o tür için veritabanından almak amacıyla tek bir sorgu çalıştır - Türün ilişkisel alanları varsa (örn.:
DirectortürününFilmtüründefilmsadlı ilişkisel alanı), mevcut yinelemede alınan tüm nesnelerin bu alanlarındaki tüm ID'leri topla (örn.:Directortüründeki tüm nesnelerinfilmsalanındaki tüm ID'ler) ve bu ID'leri ilgili tür altında kuyruğa ekle (örn.:Filmtürü altına[3, 8]ID'leri).
Yinelemeler sonunda, tüm türlerin tüm nesne verileri yüklenmiş olacak:
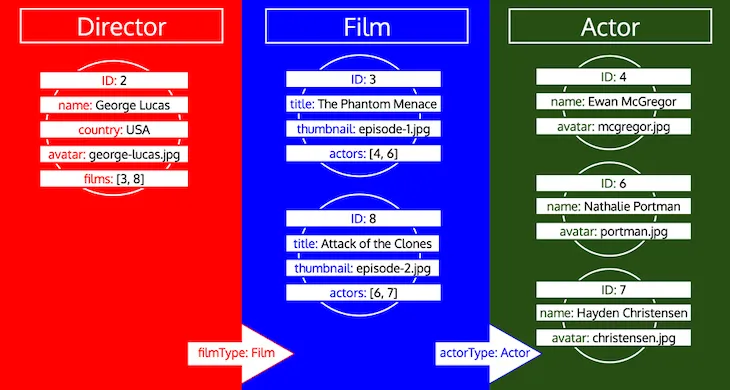
Bir türe ait tüm ID'lerin, tür kuyrukta işlenene kadar toplandığına dikkat edin. Örneğin Director türüne preferredActors adlı bir ilişkisel alan eklersek, bu ID'ler Actor türü altında kuyruğa eklenir ve Film türünün actors alanındaki ID'lerle birlikte işlenir:
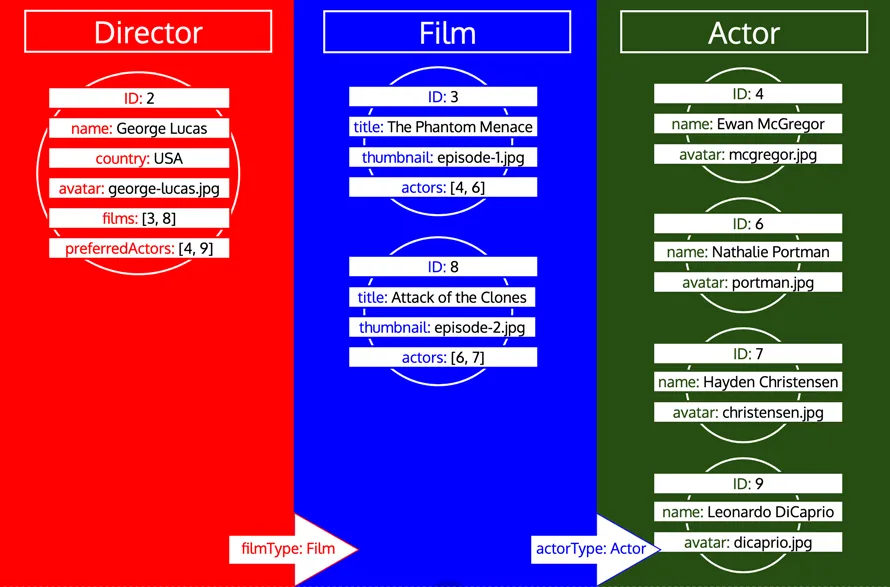
Ancak bir tür zaten işlendikten sonra o türden daha fazla veri yüklenmesi gerekirse, bu söz konusu tür üzerinde yeni bir yineleme anlamına gelir. Örneğin Author türüne preferredDirector adlı bir ilişkisel alan eklemek, Director türünün kuyruğa bir kez daha eklenmesine yol açar:
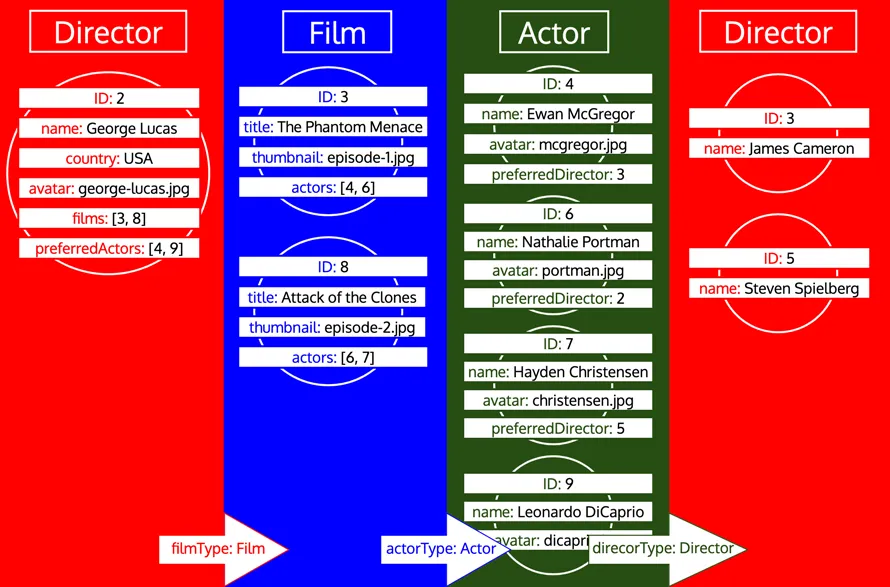
Tüm nesne verilerini aldıktan sonra, GraphQL sorgusunu yansıtacak şekilde beklenen yanıt biçimine getirmemiz gerekir. Ancak görüldüğü gibi veriler gerekli ağaç yapısına sahip değildir. Bunun yerine ilişkisel alanlar, verilerin ilişkisel bir veritabanında nasıl temsil edildiğini taklit ederek iç içe geçmiş nesnenin ID'lerini içerir. Bu karşılaştırmayı izleyerek, her tür için alınan veriler bir tablo olarak gösterilebilir:
Director türü için tablo:
| ID | name | country | avatar | films |
|---|---|---|---|---|
| 2 | George Lucas | USA | george-lucas.jpg | [3, 8] |
Film türü için tablo:
| ID | title | thumbnail | actors |
|---|---|---|---|
| 3 | The Phantom Menace | episode-1.jpg | [4, 6] |
| 8 | Attack of the Clones | episode-2.jpg | [6, 7] |
Actor türü için tablo:
| ID | name | avatar |
|---|---|---|
| 4 | Ewan McGregor | mcgregor.jpg |
| 6 | Nathalie Portman | portman.jpg |
| 7 | Hayden Christensen | christensen.jpg |
Tüm veriler tablolar halinde düzenlendiğinde ve her türün diğerleriyle nasıl ilişkilendiği bilindiğinde (yani Director, films alanı aracılığıyla Film'e, Film ise actors alanı aracılığıyla Actor'a atıfta bulunuyor), GraphQL sunucusu verileri kolayca beklenen ağaç biçimine dönüştürebilir:
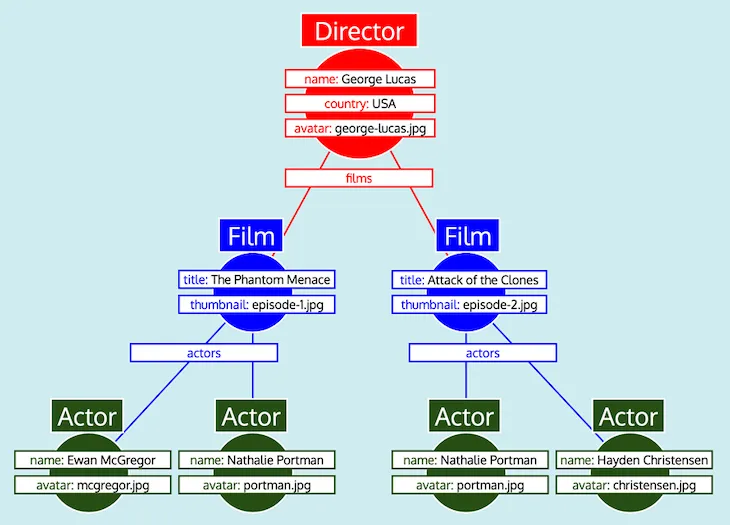
Son olarak, GraphQL sunucusu beklenen yanıt biçimine sahip ağacı çıktı olarak verir:
{
data: {
featuredDirector: {
name: "George Lucas",
country: "USA",
avatar: "george-lucas.jpg",
films: [
{
title: "Star Wars: Episode I",
thumbnail: "episode-1.jpg",
actors: [
{
name: "Ewan McGregor",
avatar: "mcgregor.jpg",
},
{
name: "Natalie Portman",
avatar: "portman.jpg",
}
]
},
{
title: "Star Wars: Episode II",
thumbnail: "episode-2.jpg",
actors: [
{
name: "Natalie Portman",
avatar: "portman.jpg",
},
{
name: "Hayden Christensen",
avatar: "christensen.jpg",
}
]
}
]
}
}
}Çözümün zaman karmaşıklığı analizi
Veri yükleme algoritmasının büyük O notasyonunu analiz ederek, girdi sayısı arttıkça veritabanına çalıştırılan sorgu sayısının nasıl büyüdüğünü anlayalım ve bu çözümün performanslı olduğundan emin olalım.
Veri yükleme motoru, her türe karşılık gelen yinelemeler halinde veri yükler. Bir yinelemeyi başlattığı anda, alınacak tüm nesnelerin tüm ID listesine zaten sahiptir; dolayısıyla ilgili nesnelerin tüm verilerini almak için tek bir sorgu çalıştırabilir. Bundan şu sonuç çıkar: veritabanına yapılan sorgu sayısı, sorguda yer alan tür sayısıyla doğrusal olarak büyür. Başka bir deyişle zaman karmaşıklığı O(n)'dir; burada n, sorgudaki tür sayısıdır (ancak bir tür birden fazla kez yinelenirse, n'ye birden fazla kez eklenmesi gerekir).
Bu çözüm son derece performanslıdır; grafiklerle çalışırken beklenen üstel karmaşıklıktan veya ağaçlarla çalışırken beklenen logaritmik karmaşıklıktan çok daha iyidir.
Uygulanan PHP kodu
Veri yükleme süreci, Component Model paketindeki Engine sınıfının getComponentData işlevinde gerçekleşir.