
Direktif Boru Hattı
Direktifler bir boru hattına yerleştirilir ve sırayla çalıştırılır. İlk tasarımları şu şekilde basittir:

Bu mimaride:
- Boru hattına giriş, alan çözümleyici tarafından sağlanan alanın değeridir
- Her direktif kendi mantığını çalıştırır ve sonucu boru hattındaki bir sonraki direktife aktarır
- Boru hattının çıktısı, tüm direktifler tarafından işlenmiş çözümlenmiş alan değeri olacaktır
Ancak bu mimari, GraphQL'den en iyi şekilde yararlanmaz. Aşağıda, Gato GraphQL'de uygulanan gerçek tasarıma ulaşıncaya kadar gerçek direktif boru hattındaki tüm aşamaların açıklaması yer almaktadır.
Direktiflerin query çözümünün yapı taşları olarak kullanılması
Başlangıçta, GraphQL sunucusunun alanı bir mekanizma aracılığıyla çözümlemesini ve ardından bu değeri direktif boru hattına girdi olarak geçirmesini düşünebiliriz.
Ancak her şeyi ele almak için tek bir mekanizmaya sahip olmak çok daha basittir: alan çözümleyicilerini çağırmak (hem alanları doğrulamak hem de çözümlemek için) zaten direktif boru hattı aracılığıyla yapılabilir. Bu durumda direktif boru hattı, query'yi çözümlemek için kullanılan tek mekanizmadır.
Bu nedenle Gato GraphQL sunucusuna iki özel direktif sağlanmıştır:
@validatealanın çözümlenebileceğini doğrulamak için alan çözümleyicisini çağırır (örn.: sözdizimi doğru, alan mevcut vb.)- Başarılı olursa,
@resolveValueAndMergealanı çözümlemek için alan çözümleyicisini çağırır ve değeri yanıt nesnesine birleştirir
Bu ikisi "sistem" direktifi olarak adlandırılan özel türdedir: yalnızca GraphQL motoruna ayrılmıştır ve her alanda örtük olarak bulunur. (Buna karşın standart direktifler açıktır: kullanıcı tarafından query'ye eklenir.)
Bu iki direktif kullanılarak şu query:
query {
field1
field2 @directiveA
}...şu şekilde çözümlenecektir:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge @directiveA
}Boru hattı artık şu şekilde görünür (boru hattının başlangıçta çözümlenmiş değeri değil, alanı girdi olarak aldığına dikkat edin):

Boru hattı yuvaları
Direktifler genellikle @resolveValueAndMerge sonrasında çalıştırılır; çünkü büyük olasılıkla çözümlenmiş alanın değerinin güncellenmesini içerirler. Ancak @validate öncesinde ya da @validate ile @resolveValueAndMerge arasında çalıştırılması gereken başka direktifler de vardır.
Örneğin:
- Bir alanı çözümlemek için geçen süreyi ölçmek amacıyla
@traceExecutionTimedirektifi, boru hattının başına@startTracingExecutionTimeve sonuna@endTracingExecutionTimealt direktiflerini yerleştirerek alan çözümlenmeden önce ve sonra geçerli saati alabilir - Bir
@cachedirektifi,@resolveValueAndMergeçalıştırılmadan önce istenen bir alanın önbellekte olup olmadığını kontrol etmeli ve bu yanıtı zaten döndürmelidir
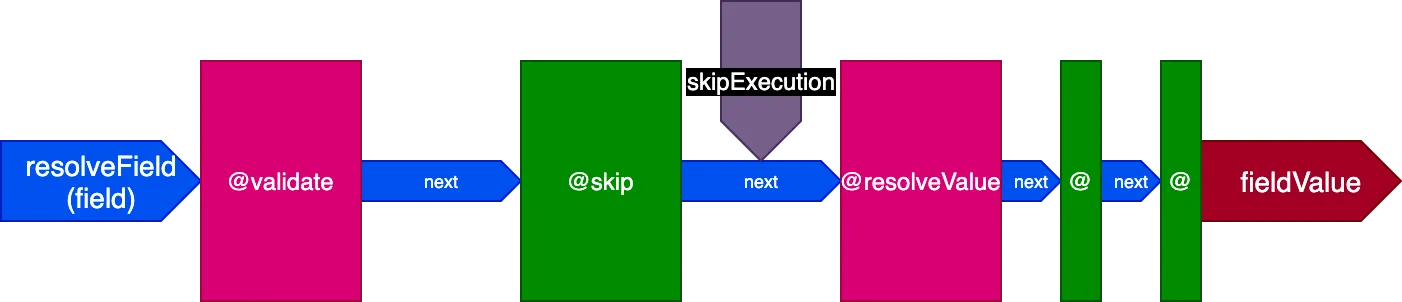
Boru hattı bunun üzerine PipelinePositions sınıfı aracılığıyla beş farklı yuva sunar ve direktif hangi yuvada çalıştırılması gerektiğini belirtir:
"beginning"yuvası: en başta"before-validate"yuvası: doğrulama gerçekleşmeden önce"middle"yuvası: doğrulamadan sonra ve alan çözümlenmeden önce"after-resolve"yuvası: alan çözümlendikten sonra"end"yuvası: en sonda
Direktif boru hattı artık şu şekilde görünür (basitleştirmek için yalnızca 3 aşama ele alınarak):

@skip ve @include direktiflerinin bu mimari sayesinde ne kadar kolaylıkla karşılanabildiğine dikkat edin: "middle" yuvasına yerleştirilen bu direktifler, skipExecution bayrağını true olarak ayarlayarak @resolveValueAndMerge direktifini (boru hattındaki sonraki aşamalardaki tüm direktiflerle birlikte) çalıştırmaması için bilgilendirebilir.
Direktifi tek bir çağrıda birden fazla alanda çalıştırma
Şimdiye kadar direktif boru hattına girdi olarak tek bir alanı ele aldık. Ancak tipik bir GraphQL query'sinde direktifleri çalıştırmak için birden fazla alan alırız.
Örneğin, aşağıdaki query'de @upperCase direktifi "field1" ve "field2" alanlarında çalıştırılır:
query {
field1 @upperCase
field2 @upperCase
field3
}Üstelik GraphQL motoru, @validate ve @resolveValueAndMerge sistem direktiflerini query'deki her alana eklediğinden, şu query:
query {
field1
field2
field3
}...şu query olarak çözümlenir:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}Bu durumda sistem direktifleri her zaman tüm alanları girdi olarak alacaktır.
Sonuç olarak direktif boru hattı, aynı anda yalnızca bir tane değil, birden fazla alanı girdi olarak alacak şekilde tasarlanmıştır:

Bu mimari daha verimlidir; çünkü bir direktifi tüm alanlar için yalnızca bir kez çalıştırmak, her alan için ayrı ayrı çalıştırmaktan daha hızlıdır ve aynı sonuçları üretir.
Örneğin şemaya erişim izni vermek için kullanıcının oturum açıp açmadığını doğrularken işlem yalnızca bir kez çalıştırılabilir. Şu kodu çalıştırmak:
if (isUserLoggedIn()) {
resolveFields([$field1, $field2, $field3]);
}şu kodu çalıştırmaktan daha verimlidir:
if (isUserLoggedIn()) {
resolveField($field1);
}
if (isUserLoggedIn()) {
resolveField($field2);
}
if (isUserLoggedIn()) {
resolveField($field3);
}Bu durum, isUserLoggedIn gibi yerel bir işlev çağrılırken büyük bir sorun gibi görünmeyebilir; ancak GraphQL aracılığıyla REST uç noktalarını çözümlemek gibi harici hizmetlerle etkileşim kurulduğunda büyük fark yaratabilir. Bu durumlarda bir işlevi birden fazla kez yerine yalnızca bir kez çalıştırmak, belirli bir işlevselliği sağlayıp sağlayamama arasındaki farkı belirleyebilir.
Bir örnek görelim. Bir @translate direktifi aracılığıyla Google Translate ile etkileşim kurulduğunda GraphQL API'sinin ağ üzerinden bağlantı kurması gerekir. Bu kodu çalıştırmak mümkün olan en hızlı yol olacaktır:
googleTranslateFields([$field1, $field2, $field3]);Buna karşın işlevi ayrı ayrı ve birden fazla kez çalıştırmak, API'nin performansını düşüren daha yüksek bir yanıt süresine yol açacak daha yüksek bir gecikme üretecektir. 3 dize çevirmek için bu belki büyük bir fark değildir (burada alan çevrilecek dizedir); ancak 100 veya daha fazla dize için kesinlikle bir etkisi olacaktır:
googleTranslateField($field1);
googleTranslateField($field2);
googleTranslateField($field3);Ayrıca bir işlevi tüm girdilerle yalnızca bir kez çalıştırmak, işlevi her alanda bağımsız olarak çalıştırmaktan daha iyi bir yanıt üretebilir. Yeniden Google Translate örneğini kullanırsak, hizmete ne kadar çok veri sağlarsak çeviri o kadar kesin olur.
Örneğin aşağıdaki kodu çalıştırırken:
googleTranslate("fork");
googleTranslate("road");
googleTranslate("sign");İlk bağımsız çalıştırmada Google, "fork" için bağlamı bilmez; bu nedenle yemek çatalı, yol ayrımı veya başka bir anlam olarak yanıt verebilir. Ancak bunun yerine şunu çalıştırırsak:
googleTranslate(["fork", "road", "sign"]);Bu daha geniş bilgi miktarından Google, "fork" sözcüğünün yol ayrımına atıfta bulunduğunu çıkarabilir ve kesin bir çeviri döndürebilir.
Boru hattındaki direktiflerin girdi alanlarını hep birlikte almasının nedeni budur; böylece her direktif bu girdiler üzerinde kendi mantığını çalıştırmanın en iyi yoluna karar verebilir (girdi başına tek çalıştırma, tüm girdileri kapsayan tek çalıştırma veya bunlar arasında herhangi bir yol).
Boru hattı artık şu şekilde görünür:
Tüm query için tek bir direktif boru hattı çalıştırma
Az önce direktif başına birden fazla alan çalıştırmanın mantıklı olduğunu öğrendik; ancak bu, tüm alanların aynı direktiflere sahip olduğu durumlarda iyi çalışır. Direktifler farklı olduğunda, uygulamayı zorlaştıran ve elde edilen faydaların bir kısmını azaltacak olan daha büyük bir karmaşıklığa yol açabilir.
Bunun nasıl gerçekleştiğini görelim. Şu query'yi ele alalım:
query {
field1 @directiveA
field2
field3
}Bu direktif şuna eşdeğerdir:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}Bu senaryoda field2 ve field3 alanları aynı direktif kümesine sahipken field1 farklı bir kümeye sahiptir; bu nedenle query'yi çözümlemek için 2 farklı boru hattı oluşturmamız gerekir:
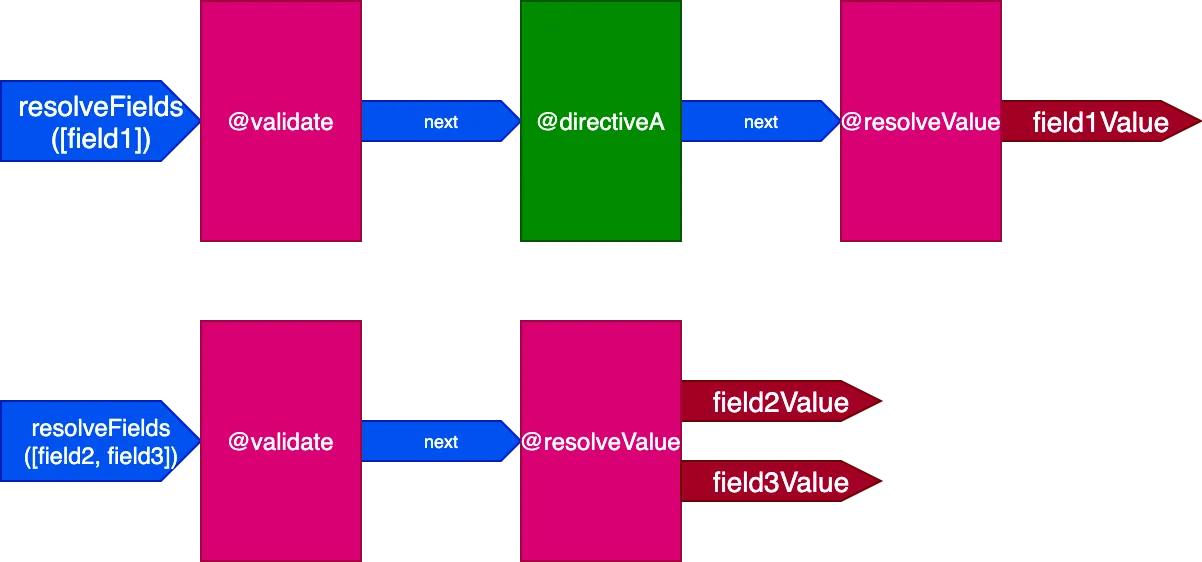
Tüm alanların benzersiz bir direktif kümesine sahip olduğu durumlarda etki daha belirgin hale gelir. Şu query'yi ele alalım:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}Bu şuna eşdeğerdir:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge @directiveB @directiveC
field3 @validate @resolveValueAndMerge @directiveC
}Bu durumda 3 alanı işlemek için 3 boru hattımız olacaktır:
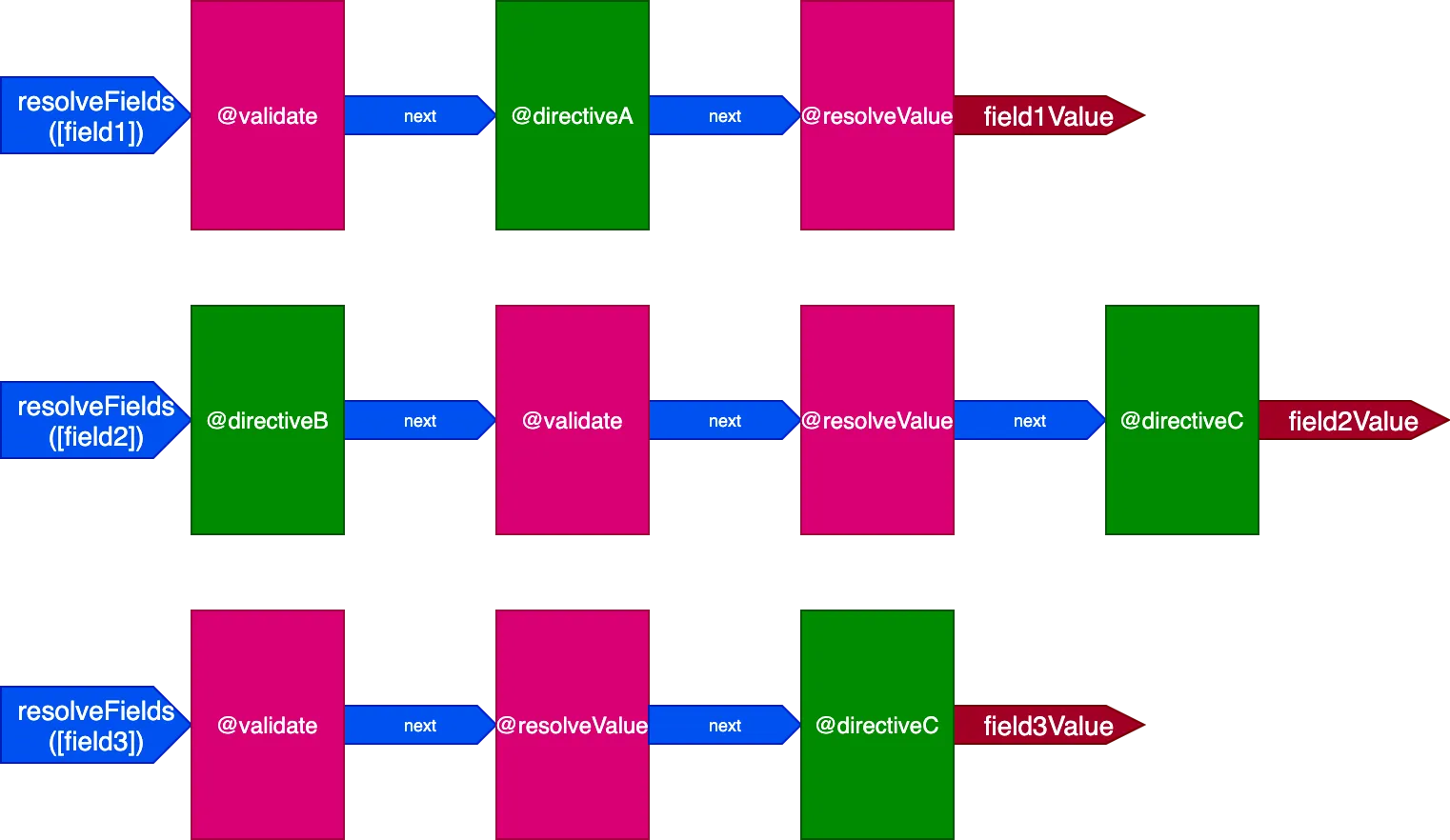
Bu durumda @validate ve @resolveValueAndMerge direktifleri 3 alana uygulanmış olsa da 3 farklı direktif boru hattı aracılığıyla çalıştırıldıklarından birbirinden bağımsız olarak çalıştırılacaklar; bu da bizi yeniden bir direktifin aynı anda tek bir öğe üzerinde çalıştırıldığı duruma götürür.
Bu sorunun çözümü birden fazla boru hattı üretmekten kaçınmak ve tüm alanlar için tek bir boru hattıyla çalışmaktır. Sonuç olarak motor artık alanları boru hattına girdi olarak geçirmez; çünkü tek bir boru hattındaki tüm direktifler aynı alan kümesiyle etkileşime girmeyecektir. Bunun yerine her direktif kendi alan listesini kendi girdisi olarak almalıdır.
Bu nedenle şu query için:
query {
field1 @directiveA
field2
field3
}...@validate ve @resolveValueAndMerge direktifleri tüm 3 alanı girdi olarak alacak ve directiveA yalnızca "field1" alanını alacaktır:
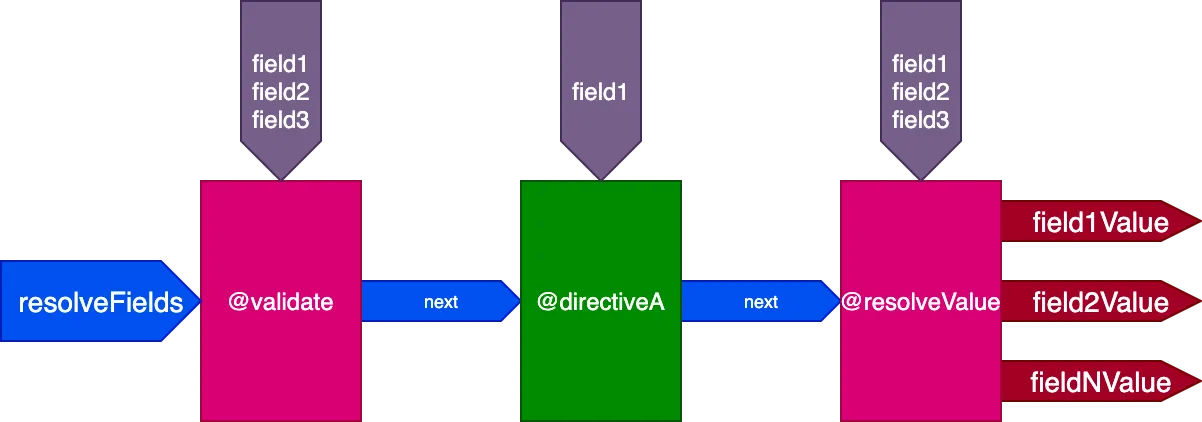
Bu query için ise:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}...@validate ve @resolveValueAndMerge direktifleri tüm 3 alanı girdi olarak alacak, directiveA yalnızca "field1" alanını, directiveB yalnızca "field2" alanını ve directiveC ise "field2" ile "field3" alanlarını alacaktır:
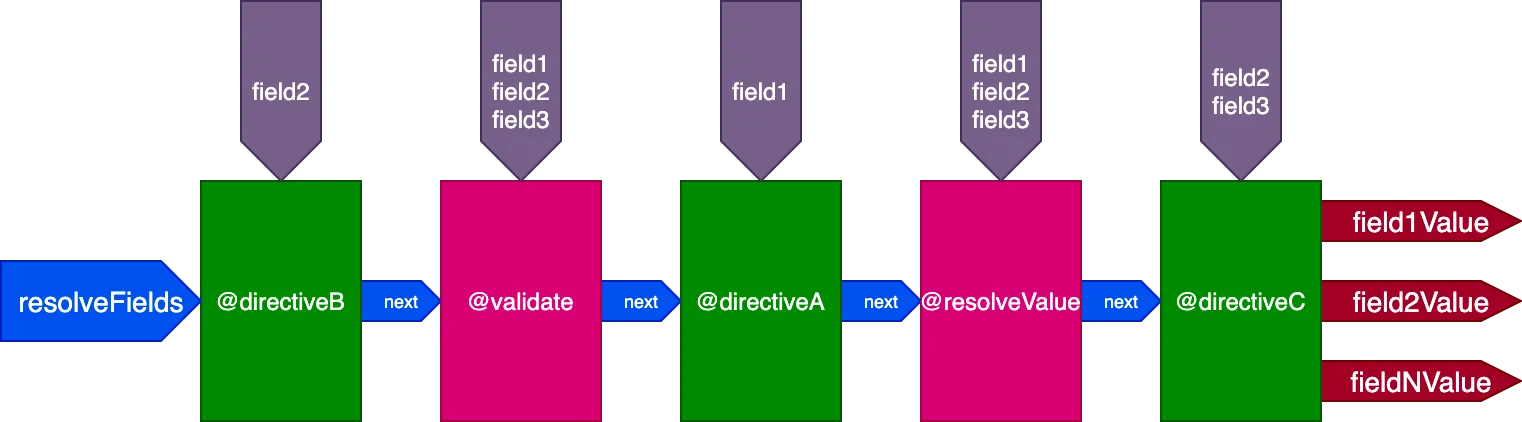
Direktif çalıştırmasını ID bazında kontrol etme
Şimdiye kadar bir aşamadaki direktif, sonraki aşamalardaki direktiflerin çalıştırılmasını skipExecution bayrağı aracılığıyla etkileyebiliyordu. Ancak bu bayrak tüm durumlar için yeterince ayrıntılı değildir.
Örneğin, alan değerini depolamak için "end" yuvasına yerleştirilen bir @cache direktifini ele alalım; böylece alan bir sonraki sorgulama sırasında "middle" yuvasına yerleştirilen @getCache direktifi aracılığıyla önbellekten alınabilir:
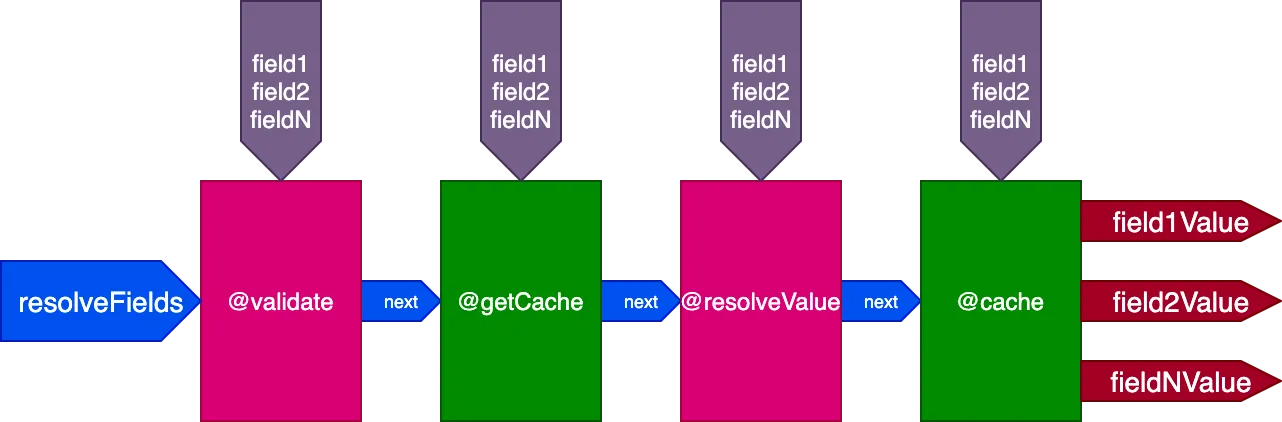
{
posts(pagination: { limit: 2 }) {
title @translate @cache
}
}Sunucu 2 kaydı alır ve önbelleğe alır. Ardından aynı query'yi çalıştırırız, ancak bu sefer 4 kayda uygulanır:
{
posts(pagination: { limit: 4 }) {
title @translate @cache
}
}Bu 2. query çalıştırılırken 1. query'den 2 kayıt zaten önbellekteydi, ancak diğer 2 kayıt değildi. Bununla birlikte skipExecution bayrağını kullanabilmek için 4 kaydın da zaten önbellekte olması gerekecekti. İlk 2 kaydı önbellekten alabilsek ve yalnızca diğer 2 kaydı çözümlesek daha iyi olurdu.
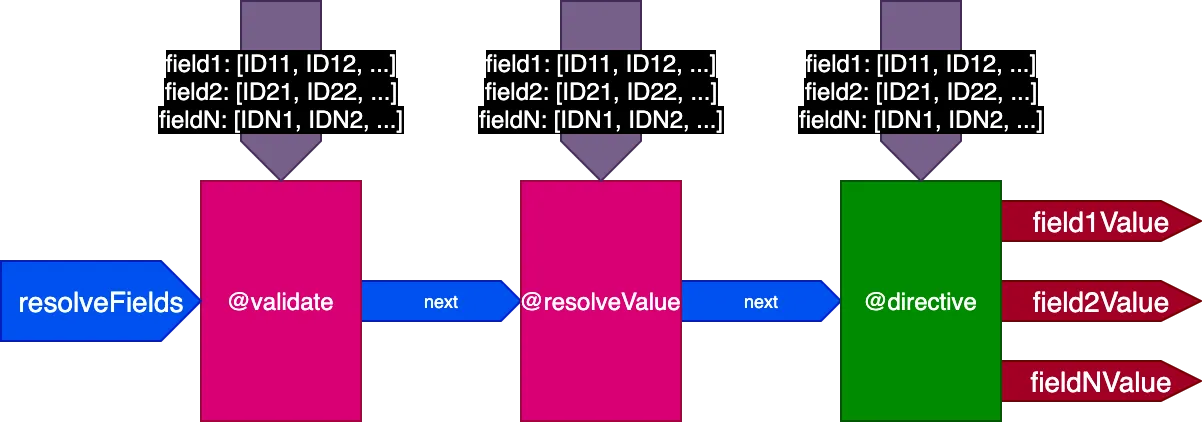
Bu nedenle boru hattının tasarımını yeniden güncelliyoruz. skipExecution bayrağını kaldırıp bunun yerine her direktife fieldIDs nesne girdisi aracılığıyla direktifin uygulanması gereken alan başına nesne ID'lerinin listesini geçiriyoruz:
{
field1: [ID11, ID12, ...],
field2: [ID21, ID22, ...],
...
fieldN: [IDN1, IDN2, ...],
}fieldIDs değişkeni her direktife özgüdür ve her direktif sonraki aşamalardaki tüm direktifler için fieldIDs örneğini değiştirebilir. Bu sayede skipExecution, yalnızca yığındaki tüm sonraki direktifler için fieldIDs değişkeninden ID'yi kaldırarak ID bazında ayrıntılı biçimde yapılabilir.
Boru hattı artık şu şekilde görünür:
Önceki örneğe uygulandığında, 2 kaydı çeviren ilk query çalıştırılırken boru hattı şu şekilde görünür:
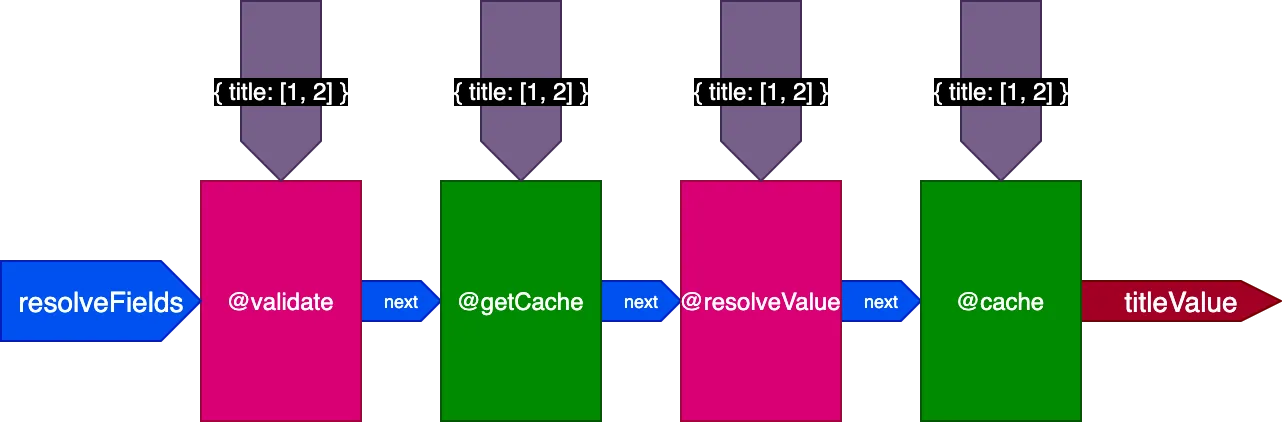
4 kaydı çeviren ikinci query çalıştırılırken @getCache direktifi tüm 4 kaydın ID'lerini alır, ancak hem @resolveValueAndMerge hem de @cache yalnızca son 2 kaydın ID'lerini alır (önbellekte olmayanlar):
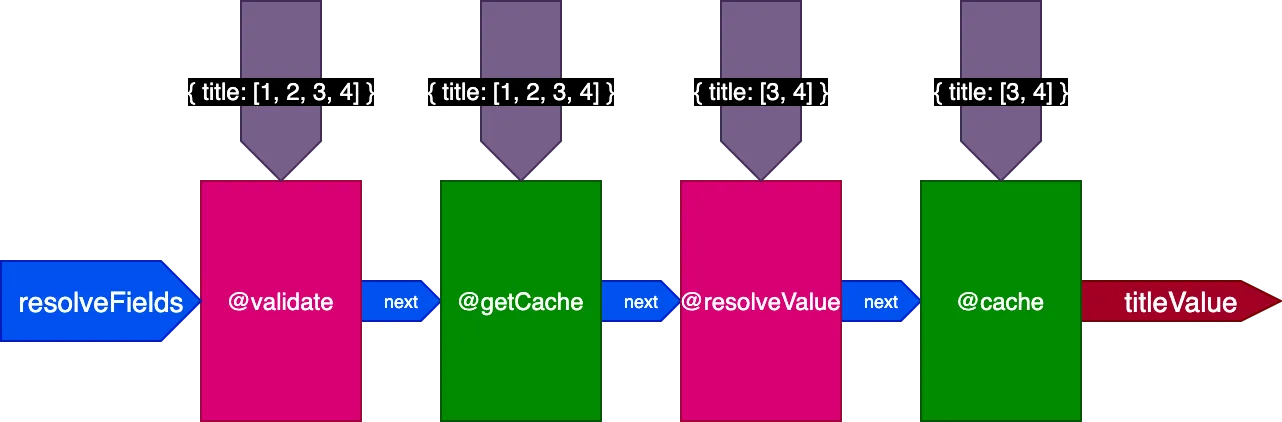
Hepsini bir araya getirme
Bu, direktif boru hattının nihai tasarımıdır:
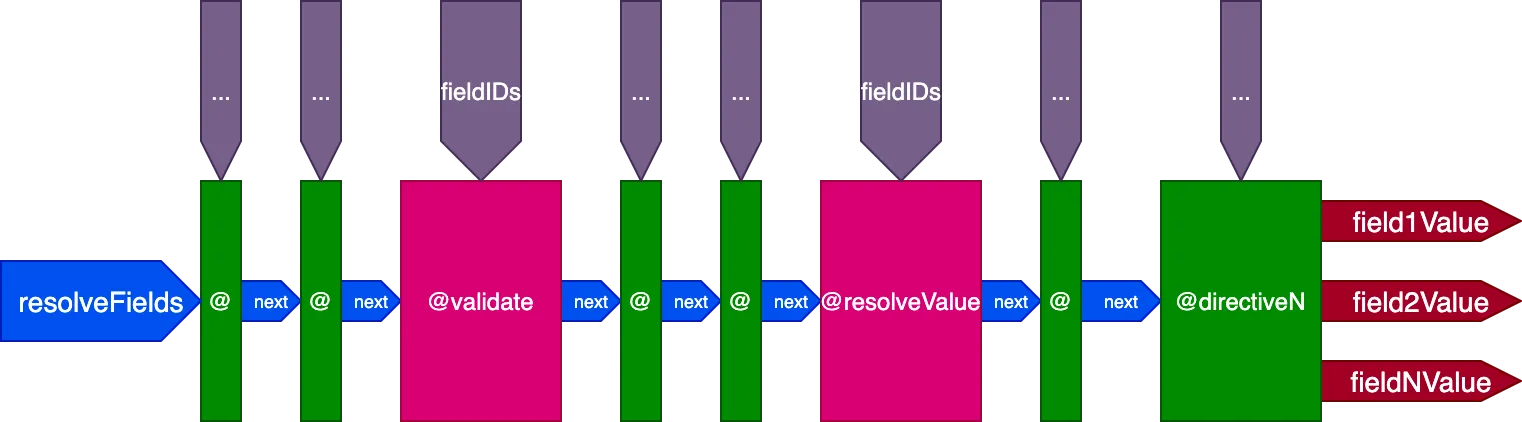
Özetlemek gerekirse, özellikleri şunlardır:
- Alan çözümleyicileri,
@validateve@resolveValueAndMergedirektifleri aracılığıyla direktif boru hattı içinden çağrılır - Direktifler 5 yuvadan herhangi birine yerleştirilebilir:
"beginning","before-validate","middle","after-validate"ve"end" - Direktifler tek bir çağrıda birden fazla alanı çözümler
- Tek bir boru hattı, query'de yer alan tüm direktifleri içerir
- Her direktif,
fieldIDsdeğişkeni aracılığıyla alan başına çözümlenecek kendi ID kümesini alır - Direktifler, boru hattındaki sonraki bir aşamadaki tüm direktifler için
fieldIDsdeğişkenini değiştirebilir