
Alan çözümleme sırasını yönetme
Multiple Query Execution tarafından sağlanan @export direktifinin amacı, bir alanın (veya alan kümesinin) değerini bir değişkene aktarmak ve bunu sorguda başka bir yerde kullanmaktır.
Bu direktif, değeri değişkene aktarmadan önce değişkenin okunması durumunda çalışmaz. Bu nedenle motorun alan yürütme sırasını kontrol etmenin bir yolunu sağlaması gerekmektedir.
Gato GraphQL, sorgunun kendisi aracılığıyla alan yürütme sırasını yönetmenin bir yolunu sunar. Motor, her tür için yinelemeli olarak veri yükler; önce sorguda karşılaştığı ilk türdeki tüm alanları çözer, ardından sorguda karşılaştığı ikinci türdeki tüm alanları çözer ve işlenecek tür kalmayana kadar bu şekilde devam eder.
Örneğin, Director, Film ve Actor türündeki nesneleri içeren şu sorgu:
{
directors {
name
films {
title
actors {
name
}
}
}
}...GraphQL motoru tarafından şu sırayla çözümlenir:

İşlendikten sonra, yüklenmemiş verileri almak için (örneğin: ek nesnelerden veya halihazırda yüklenmiş nesnelerin ek alanlarından) bir tür sorguda tekrar referans alınırsa, tür yineleme listesinin sonuna yeniden eklenir.
Örneğin, Actor'ın preferredDirector alanını da sorgularsak (bu alan Director türünde bir nesne döndürür):
{
directors {
name
films {
title
actors {
name
preferredDirector {
name
}
}
}
}
}...GraphQL motoru sorguyu şu sırayla işler:

Tek bir sorguda @export yürütmek için bunun nasıl işlediğini görelim. İlk denemede, alan yürütme sırasını düşünmeden normalde yapacağımız gibi sorguyu oluştururuz:
query GetPostsAuthorNames {
user(by: { id: 1 }) {
name @export(as: "authorName")
}
posts(filter: { search: $authorName }) {
id
title
}
}Sorgu çalıştırıldığında şu yanıtı üretir:
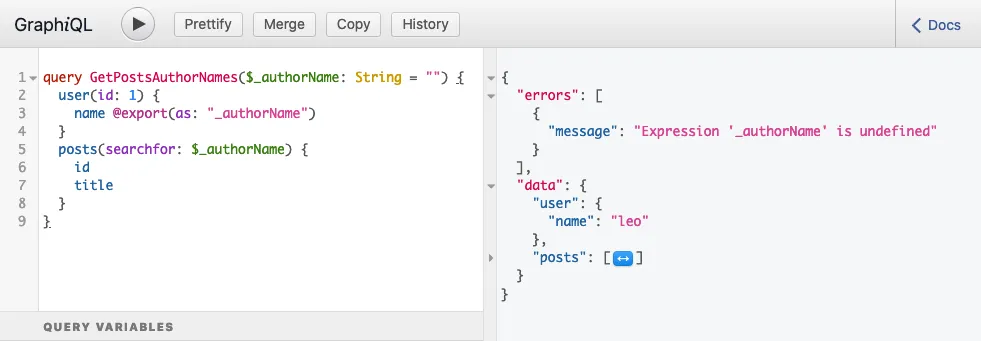
...ve şu hatayı içerir:
{
"errors": [
{
"message": "Expression 'authorName' is undefined",
}
]
}Bu hata, $authorName değişkeni okunduğunda henüz ayarlanmamış olduğu anlamına gelir; undefined durumundaydı.
Bunun neden olduğunu görelim. Öncelikle, sorguda hangi türlerin göründüğünü aşağıda yorum olarak eklenmiş haliyle analiz edelim:
# Type: Root
query GetPostsAuthorNames {
# Type: User
user(by: {id: 1}) {
# Type: String
name @export(as: "authorName")
}
# Type: Post
posts(filter: { search: $authorName }) {
# Type: ID
id
# Type: String
title
}
}Türleri işlemek ve verilerini yüklemek için veri yükleme motoru, Root sorgu türünü bir FIFO (First-In, First-Out, "ilk giren ilk çıkar") listesine ekler; bu sayede [Root], algoritmaya iletilen başlangıç listesi olur ve ardından türler üzerinde sıralı olarak şu şekilde yineler:
| # | İşlem | Liste |
|---|---|---|
| 0 | FIFO listesini hazırla | [Root] |
| 1a | Listedeki ilk türü çıkar (Root) | [] |
| 1b | Root türünden sorgulanan tüm alanları işle:→ user(by: {id: 1})→ posts(filter: { search: $authorName })Türlerini ( User ve Post) listeye ekle | [User, Post] |
| 2a | Listedeki ilk türü çıkar (User) | [Post] |
| 2b | User türünden sorgulanan alanı işle:→ name @export(as: "authorName")Skaler bir tür ( String) olduğundan listeye eklenmesine gerek yok | [Post] |
| 3a | Listedeki ilk türü çıkar (Post) | [] |
| 3b | Post türünden sorgulanan tüm alanları işle:→ id→ titleBunlar skaler türler ( ID ve String) olduğundan listeye eklenmelerine gerek yok | [] |
| 4 | Liste boş, yineleme sona erer. |
Burada sorunu görebiliriz: @export 2b adımında yürütülür, ancak 1b adımında okunmuştur.
Alan yürütme akışını kontrol etmemiz gereken yer burasıdır. Uygulanan çözüm, Root türünden self alanını yapay olarak sorgulayarak aktarılan değişkenin ne zaman okunacağını geciktirmektir.
self alanı, adından da anlaşılacağı gibi aynı nesneyi döndürür; Root nesnesine uygulandığında aynı Root nesnesini döndürür. "Zaten kök nesneye sahipsem, neden onu tekrar almam gereksin?" diye merak edebilirsiniz. Çünkü motorun algoritması bu yeni Root referansını FIFO listesinin sonuna eklemek zorunda kalacak ve biz yinelemelerin her birinden önce veya sonra sorgulanan alanları bilinçli olarak dağıtabiliriz.
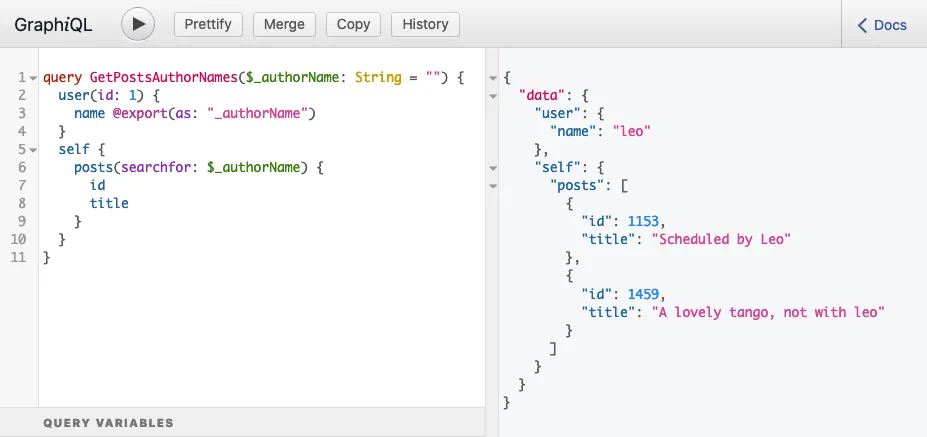
Bu nedenle posts(filter:{ search: $authorName }) alanı yukarıdaki sorguda bir self alanının içine yerleştirilmiştir ve sorgu çalıştırıldığında beklenen yanıtı üretir:
query GetPostsAuthorNames {
user(by: {id: 1}) {
name @export(as: "authorName")
}
self {
posts(filter: { search: $authorName }) {
id
title
}
}
}
Bu sorgunun neden düzgün çalıştığını anlamak için türlerin işlenme sırasını inceleyelim:
| # | İşlem | Liste |
|---|---|---|
| 0 | FIFO listesini hazırla | [Root] |
| 1a | Listedeki ilk türü çıkar (Root) | [] |
| 1b | Root türünden sorgulanan tüm alanları işle:→ user(by: {id: 1})→ selfTürlerini ( User ve Root) listeye ekle | [User, Root] |
| 2a | Listedeki ilk türü çıkar (User) | [Root] |
| 2b | User türünden sorgulanan alanı işle:→ name @export(as: "authorName")Skaler bir tür ( String) olduğundan listeye eklenmesine gerek yok | [Root] |
| 3a | Listedeki ilk türü çıkar (Root) | [] |
| 3b | Root türünden sorgulanan alanı işle:→ posts(filter:{ search: $authorName })Türünü ( Post) listeye ekle | [Post] |
| 4a | Listedeki ilk türü çıkar (Post) | [] |
| 4b | Post türünden sorgulanan tüm alanları işle:→ id→ titleBunlar skaler türler ( ID ve String) olduğundan listeye eklenmelerine gerek yok | [] |
| 5 | Liste boş, yineleme sona erer. |
Artık sorunun çözüldüğünü görebiliriz: @export 2b adımında yürütülür ve 3b adımında okunur.
Multiple Query Execution, sorguları ayrıştırırken tam olarak bunu yapar: GraphQL belgesini self alanları ekleyerek dönüştürür; böylece her işlemdeki alanlar yalnızca önceki tüm işlemlerdeki tüm alanlar çözümlendikten sonra yürütülür.